Uwaga: przeglądasz tę stronę na urządzeniu o niewielkim ekranie (szerokość < 640px). Niektóre zamieszczone w artykule ilustracje i animacje mogą stać się nieczytelne po dopasowaniu ich do rozdzielczości tego ekranu.
Yestok.pl
Jerzy Moruś
© Wszystkie prawa zastrzeżone. Wykorzystanie całości serwisu lub jego fragmentów bez pisemnej zgody autora zabronione.
Korespondencja seryjna w programie Writer.
Opracowanie powstało w oparciu o wersję programu istniejącą w trakcie jego pisania, Libre Office: 4.0.5, Apache OpenOffice: 3.4.1.
- Wprowadzenie.
- Źródło danych.
- Tworzenie baz danych.
- Korespondencja seryjna.
- Dokument wyjściowy.
- Emisja dokumentów seryjnych.
- Korespondencja seryjna – Kreator.
- Drukowanie kopert.
- Drukowanie etykiet.
- Załącznik do testowania.
Wprowadzenie.
Korespondencja seryjna… tym terminem twórcy edytorów tekstów określili specyficzny rodzaj dokumentów. Chodzi o sytuację, w której ta sama treść, w zindywidualizowanej postaci, ma zostać wielokrotnie wydrukowana. Powszechnie przywoływanym przykładem takiego rodzaju dokumentów jest taki, który w nagłówku kolejnych drukowanych egzemplarzy zawiera imię i nazwisko adresata dokumentu i ewentualnie dalsze dane personalne, np. adres.
Rzeczywiście, korespondencja seryjna prawie zawsze dotyczyć będzie osób i informacji z nimi związanych. Różnego rodzaju zawiadomienia (o czynszach, składkach, należnościach), dyplomy (sportowe, uznania, okolicznościowe), pisma okólne, spełniają te kryteria. Każda osoba, dla której powstanie osobny dokument może mieć także różne dane, przeznaczone tylko dla niej, umieszczane w takim dokumencie. Określenie „osoba” ma tutaj zresztą charakter umowny. Kryć się pod nią mogą także nazwy firm lub inne informacje, które ze względu na powiązania miedzy sobą, mogą stanowić zestaw pozwalający utworzyć indywidualny dokument.
Niespersonalizowanym przykładem takich dokumentów mogą być na przykład metki cenowe umieszczane w sklepach przy towarach. Wyglądają tak samo, ale zawierają nazwę towaru, nazwę producenta, wagę i cenę, powiązane w jeden dokument.
Wytwarzanie dokumentów korespondencji seryjnej, bo tak nazywa się w terminologii edytorów tekstowych te zindywidualizowane dokumenty, opiera się w programie Writer o wykorzystanie tak zwanego dokumentu wyjściowego, będącego w istocie zobrazowaniem ostatecznej postaci jednostkowego dokumentu korespondencji seryjnej, oraz źródła danych, zawierającego zorganizowaną strukturę informacji, niezbędnych do powstania takich indywidualnych dokumentów. Dokument wyjściowy, w miejscach w których ma się znaleźć informacja indywidualna, przewidziana dla konkretnego dokumentu, ma wstawione symbole zastępcze, sygnalizujące miejsca przeznaczone dla tych informacji. Symbole zastępcze podczas emisji dokumentów seryjnych, zostaną zastąpione wartościami związanymi z konkretnym egzemplarzem i dopiero wtedy taki dokument zostanie wyemitowany. Następnie, dokument wyjściowy pobierze zestaw wartości niezbędnych dla utworzenia kolejnego egzemplarza i także go wyemituje. Proces ten będzie się powtarzał do wyczerpania zestawu tych wartości lub do spełnienia kryteriów ustalonych przez użytkownika.
Dokument wyjściowy utworzony jest jak każdy inny dokument programu Writer. Jedyną różnicą w stosunku do zwykłych dokumentów jest to, że ma on osadzone w swej treści symbole zastępcze, nazywane także polami listu seryjnego.
Źródło danych.
Źródło danych, z którego korzysta korespondencja seryjna musi zostać zarejestrowane w pakiecie (x)Office jako baza danych. Samo źródło zawiera zestawy wartości przeznaczonych dla pojedynczego dokumentu końcowego. Zestawy tych wartości zapisywane są wierszami, dlatego tworzą swego rodzaju tabelę, kolumny takiej tabeli zawierają jednorodne informacje. Każdy wiersz takiego zapisu nazywamy „rekordem” a każdą kolumnę w zestawie nazywamy polem. Mówimy zatem, że rekord składa się z pól. Każdemu polu w źródle danych przypisana jest nazwa identyfikująca to pole. Nazwa ta musi być unikatowa w obrębie konkretnego źródła danych. To właśnie nazwa pola ze źródła danych jest umieszczana w dokumencie wyjściowym jako pole listu seryjnego.
Źródło danych może być dokumentem różnego typu. Może to być arkusz kalkulacyjny Calc albo Excel, macierzysta baza danych pakietu (x)Office, zgodna z systemem baz danych HSQL, wykorzystująca program Base (także wchodzący w skład pakietu), lub baza danych innego systemu np. Access, MySQL czy inna, książki adresowe programu Outlook, systemu Windows lub programu Thunderbird, a nawet zwykły tekst, jeśli zostanie przygotowany zgodnie z pewnymi regułami. Zestaw danych musi tworzyć, jak już wspomniałem, pewną strukturę tabelaryczną. Dane zawarte w bazach danych tworzą taką strukturę z racji samej organizacji baz. To samo dotyczy także książek adresowych. Konstrukcja programu arkusza kalkulacyjnego, narzuca właściwie zorganizowanie danych w postaci tabel. Zwykły tekst także może być źródłem danych, pod warunkiem, że wartości tworzące to źródło są zapisane wierszami, zawarte w nich dane występują zawsze w tej samej kolejności, i oddzielone są od siebie takim samym znakiem separującym, np. średnikiem, znakiem tabulacji lub innym, który nie będzie częścią którejś z wartości. Jeśli w jakimś wierszu, konkretna wartość nie występuje, pomija się ją, wstawiając jednak odpowiedni znak separujący. Pierwszym wierszem takiego zestawienia powinien być wiersz definiujący nazwy przypisane kolejnym wartościom, one także muszą być rozdzielone przyjętym znakiem separatora.
Zestawienia oparte o bazy danych albo książki adresowe, mają nazwy pól utworzone w momencie definiowania struktury bazy i jako użytkownicy nie mamy już na nie wpływu. W pozostałych przypadkach, czyli wykorzystania arkusza kalkulacyjnego bądź pliku tekstowego, nazwy pól definiuje pierwszy wiersz tabeli w arkuszu lub pierwszy wiersz pliku tekstowego. Pierwszy wiersz odgrywa zatem ważną rolę w tych zestawieniach bo nazwy pól, stając się polami listu seryjnego, wskażą gdzie i jaka informacja ma pojawić się w dokumentach seryjnych.
Poniżej pokazuję przykładowe źródło danych przedstawione w dwóch postaciach. Źródło zawiera imiona i nazwiska uczniów, informację o płci oraz oceny z siedmiu przedmiotów. Nazwy pól jednoznacznie określają charakter informacji przechowywanej w konkretnym polu.

Źródło przygotowano w programie arkusza kalkulacyjnego musi rozpoczynać się w pierwszej komórce arkusza, a jej pierwszy wiersz musi zawierać nazwy identyfikujące zawartość kolumn. Nazwy te staną się polami listu seryjnego.

Źródło w postaci zwykłego tekstu. Wykaz ten, to po prostu zapisane wierszami poszczególne informacje. Pierwszy wiersz takiego pliku określa nazwy kolejnych pól. Jako separator tych informacji wykorzystano w tym przykładzie znak średnika. Plik tego typu musi być plikiem niesformatowanym, czyli wyłącznie tekstowym. Pliki takie mają najczęściej w rozszerzeniu nazwy litery TXT. Wymogi te spełniają także pliki z rozszerzeniem CSV, są to bowiem pliki tekstowe generowane z różnych programów, w których poszczególne informacje rozdzielane są przecinkami. Stąd rozszerzenie nazwy o litery CSV, jako akronim słów „Comma Separated Values” (wartości oddzielane przecinkami). Rozszerzenie nazwy nie ma tu jednak podstawowego znaczenia, ważna jest struktura takiego zestawienia.
Podsumowując dotychczasowy opis, przygotowanie korespondencji seryjnej wymaga dokumentu wyjściowego, i powiązanego z nim, źródła danych. Bardzo często źródło danych nie jest tworzone przez osobę przygotowującą korespondencję, gdyż takie dane mogą być gromadzone, edytowane i udostępniane na poziomie całej organizacji, tworząc struktury złożone z wielu tysięcy rekordów.
Pakiet (x)Office umożliwia dostęp do dowolnego źródła poprzez bazę danych zarejestrowaną w tym systemie. Jedną z takich baz omawiałem opisując zasady tworzenia bibliografii w programie Writer. Zatem aby wykorzystać źródło danych, trzeba je zarejestrować jako bazę danych.
Aby zobaczyć jakie bazy danych są już zarejestrowane w (x)Office należy wywołać polecenie „Narzędzia – Opcje…” i w otwartym oknie dialogowym, po lewej stronie, rozwinąć pozycję „(x)Office Base” a następnie zaznaczyć „Bazy danych”. Otwarte zostanie okno prezentujące wszystkie zarejestrowane, a więc dostępne do wykorzystania, bazy danych. Takie przykładowe okno przedstawia rys. 2.

Nazwy plików baz danych wyświetlanych w tym oknie mają rozszerzenie ODB. Pliki te nie zawsze są jednak rzeczywistymi plikami zawierającymi dane. Te, jak wspomniałem, znajdują się w źródle danych. Plik ODB jest w takim przypadku swego rodzaju transformacją źródła danych na bazę danych. Oznacza to, że usunięcie pliku ODB z systemu nie oznacza usunięcia samego źródła a jedynie niemożność wykorzystania tego źródła bez ponownego utworzenia dla niego pliku ODB. W tym miejscu warto wspomnieć, że terminem „baza danych” określamy także pewne zagregowane struktury danych zapisane w jednym lub wielu powiązanych plikach zgodnie z przyjętymi regułami. Takie bazy danych także muszą mieć swój plik ODB. W sytuacji utworzenia bazy danych w macierzystym systemie (x)Office, czyli w HSQL, plik ODB jest jednocześnie plikiem źródła i usunięcie go usunie niestety także zgromadzone dane.
Przyciski tego okna pozwalają na:
„Nowy…” – pozwala dodać nową bazę danych do zarejestrowanych baz. Aby zrealizować to zadanie musi już istnieć plik ODB wiążący się z jakimś źródłem danych. Plik ten należy wskazać w dodatkowym oknie lokalizacji pliku. Okno to przedstawione jest poniżej.

W oknie tym podać także trzeba nazwę pod jaką baza będzie zarejestrowana. Proponowaną nazwą bazy jest nazwa pliku ODB, bez rozszerzenia, ale można wpisać swoją własną nazwę. To przez tę nazwę baza danych będzie dostępna w oprogramowaniu (x)Office.
„Usuń” – pozwala usunąć zarejestrowaną bazę z listy. Plik ODB nie jest usuwany. Usuwana jest informacja o zarejestrowaniu bazy. Można zatem taką bazę ponownie zarejestrować.
„Edycja…” – ten przycisk otwiera, dla wybranej bazy, okno analogiczne do pokazanego na rys. 3, pozwalając zmienić nazwę bazy, bądź wskazać inną lokalizację i inny plik ODB.
Tworzenie baz danych.
Aby jednak móc rejestrować i wyrejestrowywać bazy danych, należy je utworzyć. Za utworzenie bazy danych odpowiada polecenie „Plik – Nowy – Baza danych”, wybrane z listy jak na rys. 4.

Teraz, przechodząc przez kolejne okna dialogowe, można zrealizować proces utworzenia bazy.
Pierwszym oknem jest okno pokazane poniżej.

Opcja „Utwórz nową bazę danych”, pozwala utworzyć zupełnie nową bazę, tym razem w znaczeniu zgromadzonych w niej danych, opartą o macierzysty format baz danych pakietu (x)Office. Wymaga to znajomości zasad tworzenia systemów baz danych. Kontynuowanie tej opcji prowadzi do wywołania programu Base, wchodzącego w skład pakietu (x)Office i wykonywanie dalszych działań w tym programie.
Druga opcja, „Otwórz istniejący plik bazy danych”, pozwala działać na już istniejących plikach baz i także wymaga znajomości wspomnianych powyżej zasad. Tutaj także kontynuowanie tej opcji prowadzi do wywołania programu Base.
To opracowanie nie jest poświęcone bazom danych, więc dwie pierwsze opcje nie będą tu omówione.
Trzecia opcja, „Połącz z istniejącą bazą danych”, pozwala wybrać z jakim modelem zagregowanych danych chcemy połączyć tworzony plik ODB. Ilustracja pokazuje bogatą listę możliwości. W przypadku tego opracowania pokażę najpierw utworzenie powiązania z plikiem arkusza kalkulacyjnego. Wybór opcji „Arkusz kalkulacyjny” wywoła kolejne okno, które zamieszczam poniżej.

W tym oknie wystarczy wskazać plik arkusza kalkulacyjnego Calc lub Excel, który ma być źródłem danych. Jeśli skoroszyt arkusza składa się z kilku arkuszy, to każdy z nich będzie dostępny jako źródło pod warunkiem że dane zorganizowane zostaną zaczynając od komórki A1 w arkuszu.
Gdyby w oknie dialogowym pokazanym na rys. 5. wybrano opcję „Tekst”, a nie „Arkusz kalkulacyjny”, wówczas otwarte zostałoby inne okno, takie jak poniżej.

W tym oknie nie wskazuje się konkretnej nazwy pliku typu tekstowego lecz folder, w którym znajdują się pliki wybranego typu. Jeśli we wskazanym folderze będzie kilka plików wybranego typu, to wszystkie zostaną zaakceptowane. Uprzedzę od razu, że z każdego z nich można będzie korzystać niezależnie. Rozszerzenie nazwy pliku może być dowolne, ważnym jest aby zawartość odpowiadała wspomnianym już powyżej regułom. Należy dodatkowo określić w parametrach znaczenie występujących w nim znaków, pozwalających interpretować zawartość takich plików.
Proces ten kończy ostatnie, pokazane poniżej, okno dialogowe.

Tutaj trzeba podjąć dwie decyzje. Pierwszą, czy utworzona baza danych ma zostać od razu zarejestrowana w pakiecie (x)Office. Jeśli bazy nie zarejestrujemy, to będzie można to zrobić później, w opisany wcześniej sposób (zob. rys. 2).
Druga decyzja dotyczy tego, czy po zapisaniu bazy, ma ona zostać otwarta do edycji. Edycja umożliwia dostęp do bazy rozumianej jako fizycznie zagregowane dane i realizowana jest za pomocą programu Base. Wspomniałem, że opracowanie to nie dotyczy baz danych, więc powinniśmy wyczyścić to pole wyboru.
Zakończenie tej procedury zamyka wszystkie okna dialogowe. Od tego momentu można korzystać z bazy danych. Dostęp do baz możliwy jest po użyciu poleceń „Widok – Źródła danych”, po kliknięciu w ikonkę „Źródła danych” znajdującą się na pasku narzędziowym albo po naciśnięciu klawisza F4. Uwaga: W wersji LibreOffice skrót klawiaturowy F4 został od wersji 5-tej zastąpiony kombinacją CTRL+SHIFT+F4.Przykładowy efekt widoczny jest poniżej.

Ilustracja pokazuje, że z poziomu programu Writer można wykorzystać dostęp do czterech zarejestrowanych baz danych.
Każda baza danych składa się z tabel i kwerend. Tabela to kompletny zestaw wszystkich danych zgromadzonych w jednej strukturze. Tabelą będzie więc arkusz, jeśli baza utworzona jest w oparciu o plik arkusza kalkulacyjnego. Jeśli plik arkusza kalkulacyjnego wykorzystuje kilka arkuszy, to każdy z nich będzie w takiej bazie odrębną tabelą. Dla bazy opartej o strukturę tekstową, tabelą będzie każdy plik tekstowy zidentyfikowany w folderze wskazanym przy tworzeniu bazy.
Kwerenda to „wyciąg” z bazy danych. Jeśli użytkownik korzysta z pewnych wybranych rekordów bazy danych, to może utworzyć właśnie kwerendę, w której zdefiniowane zostaną warunki wyboru rekordów i pola jakie będą interesujące dla konkretnego zagadnienia. Takim zdefiniowanym kryteriom przypisuje się nazwę poprzez którą można dotrzeć do wybranych rekordów. Kwerendy definiuje się w programie Base a nie jest on treścią tego opracowania.
Na ilustracji powyżej widoczna jest m. in. baza „Baza txt”. Rozwinięcie znaku „plus” obok nazwy bazy pokaże z ilu tabel i z ilu kwerend się ona składa. Pokazuję to na rysunku 10.

W tym przypadku, w folderze znajdowały się dwa pliki tekstowe, „Seryjna-źródło.txt” i „Seryjna źródło2.txt”. Nazwy te stały się nazwami dwóch tabel dostępnych w tej bazie. Ponadto zdefiniowałem dwie kwerendy dotyczące tabeli „Seryjna-źródło”, jednej nadając nazwę „Dziewczęta” a drugiej „Chłopcy”. Jak łatwo zorientować się po nazwach, kwerenda „Dziewczęta” zawiera rekordy źródła dotyczące tylko dziewcząt. Kwerenda „Chłopcy” – tylko chłopców.
Zamykając na tym etapie problematykę baz danych, dodam że bazy utworzone w oparciu o książki adresowe, pliki tekstowe oraz pliki arkuszy kalkulacyjnych, mogą być używane wyłącznie w trybie do odczytu. To znaczy, że nie można w nich dokonywać zmian z poziomu programu Base. Jeśli w źródle danych mają zajść zmiany, mają być dopisane nowe rekordy, usunięte zbędne albo zmieniona zawartość jakichś pól danych, to wykonać to należy w jego macierzystym programie, tym w którym zostało utworzone.
Korespondencja seryjna.
Aby omówić tworzenie korespondencji seryjnej, wymyśliłem w miarę realny – jak sądzę – przykład. Jako wychowawcy klasy, przygotujemy dla każdego z rodziców informację o wynikach w nauce jego dziecka. Informacja taka przygotowywana jest zazwyczaj na wywiadówkę po pierwszym półroczu i przed zakończeniem roku. Powinna ona zawierać imię i nazwisko dziecka, uzyskane oceny końcowe z poszczególnych przedmiotów, oraz średnią z tych ocen. Myślę, że ten przykład będący podstawą dalszych rozważań, dobrze pokaże możliwości korespondencji seryjnej z jednej strony, a z drugiej, po odpowiednim dopasowaniu i przeróbkach, może przydać się nauczycielom. W sumie taki dokument powinien wyglądać mniej więcej tak, jak na ilustracji poniżej.

Zakładam też, że źródłem danych będzie arkusz kalkulacyjny, być może utrzymywany na szkolnym serwerze plików, zawierający informacje o wszystkich uczniach, przedmiotach i stopniach z tych przedmiotów otrzymanych. Źródło to przedstawia ilustracja 12. Zostanie ono użyte do realizacji zasygnalizowanego problemu. Czytelnik, który chciałby to zagadnienie przećwiczyć po swojemu, będzie mógł pobrać ten plik i wykorzystać do testów we własnym zakresie.

Jak widać źródło zawiera imiona i nazwiska uczniów, informację o klasie i oddziale klasy (pole „gr”), płci i stopniach z przedmiotów, których początkowe litery tworzą jednocześnie nazwę pola. Widać też, że pierwszy wiersz tabeli określa nazwy poszczególnych pól (kolumn). Plik tego arkusza został zarejestrowany jako baza o nazwie „xlsx”
Dokument wyjściowy.
Przygotowanie dokumentu wyjściowego w pierwszej kolejności wymaga umieszczenia w nim treści która będzie niezmienna. Taki surowy przygotowany dokument może wyglądać tak.

Na ilustracji czerwonymi prostokątami zaznaczyłem miejsca, w których powinna pojawić się informacja pobrana ze źródła danych. Prostokąty zielone wskazują miejsca, w których informacje także są zmienne ale zależą od dokumentu i innych okoliczności związanych z dokumentem.
Jako pierwsze omówię pola listu seryjnego, czyli informacje przenoszone bezpośrednio ze źródła. W przypadku tego przykładu będą to: imię i nazwisko ucznia, klasa oraz stopnie z poszczególnych przedmiotów. Writer umożliwia wstawianie tych pól na dwa sposoby. Pierwszy, wydaje mi się mniej skomplikowany, wymaga aby wybrać tabelę lub kwerendę, która jest źródłem danych i pokazać ją w widoku dokumentu. Najprościej w tym celu jest skorzystać z klawisza F4 i wybrać stosowną tabelę. W tym przykładzie została wskazana tabela „Arkusz1” w bazie „xlsx”.

W widoku źródła pokazane są wszystkie nazwy pól i tyle rekordów źródła, ile zmieści się w przewidzianym do tego obszarze. Korzystając z tego widoku, wystarczy kliknąć nazwę potrzebnego pola i przeciągnąć ją w to miejsce dokumentu, w którym ma pojawić się w przyszłości jego zawartość . W dokumencie nazwa pola pojawi się w charakterystycznych, trójkątnych nawiasach. Wskazanie takiego pola myszką, wyświetli „dymek” informujący jakie pole, z jakiej tabeli i z jakiej bazy, zostało umieszczone w dokumencie. W ten sam sposób, po imieniu, można wstawić pole zawierające nazwisko.
Aby w tym przykładzie określić klasę, trzeba wstawić dwa pola, pole „Klasa” i pole „gr”, gdyż dopiero te dwa, umieszczone obok siebie pola, utworzą ostateczny kod klasy. Można to zrobić pokazaną powyżej metodą, ale omówię teraz drugi sposób umieszczania pól seryjnych. Nie wymaga on otwierania widoku źródła. Należy umieścić kursor tekstowy w miejscu, w którym pole ma zostać umieszczone i wywołać polecenia „Wstaw – Pola – Inne…” lub skorzystać ze skrótu klawiaturowego „CTRL+F2”. Otwarte zostanie okno dialogowe „Pola”, przedstawione na poniższej ilustracji.

To okno „obsługuje” kilka kategorii pól programu Writer. Pola listu seryjnego dostępne są w kategorii „Baza danych”. W obszarze definiowania typu pola, wskazuję „Pole listu seryjnego”. W obszarze wyboru bazy danych, wybieram właściwą bazę, następnie tabelę i rozwijam tę tabelę, uzyskując dostęp do nazw pól. Zaznaczone pole można wstawić do dokumentu przyciskiem „Wstaw”, albo przeciągając je we właściwe miejsce. Okno to nie zostaje zamknięte po wykonaniu tej operacji, więc można wskazać nowe miejsce w dokumencie i wstawić tam kolejne potrzebne pole albo je w to miejsce przeciągnąć. Okno zamykane jest przyciskiem „Zamknij”.
Wykorzystując dowolną z tych metod, przeniosłem pozostałe pola listu seryjnego, w wyniku czego tworzony dokument przybrał taką postać:

Zazwyczaj w tym momencie chcielibyśmy sprawdzić, czy pola listu seryjnego są prawidłowo przenoszone do dokumentu. Można to zrobić wydając polecenie „Dane na pola” dostępne w pasku narzędziowym wyświetlanego źródła. Na poniższej ilustracji ikonka reprezentująca to polecenie otoczona jest czerwonym okręgiem.

Aby jednak skorzystać z tego polecenia, trzeba kliknąć myszką z lewej strony wybranego rekordu, tam gdzie na ilustracji widać zielony znacznik, tak aby cały rekord został zaznaczony, i dopiero wtedy kliknąć ikonkę „Dane na pola”. Dane z zaznaczonego rekordu zostaną pokazane w miejscu pól listu seryjnego. Aby obejrzeć dokument z innymi danymi, należy wybrać inny rekord i ponownie użyć tej ikonki. Po przeniesieniu danych na pola nie można już powrócić do widoku pól zawartych wewnątrz nawiasów < i >.
Przeniesienie danych na pola powoduje jeszcze jeden skutek, nie widać mianowicie czy wpisany tekst jest wynikiem osadzenia pola czy treścią wpisaną w zwykły sposób. Writer umożliwia zlokalizowanie wszystkich pól w dokumencie, poprzez wybranie polecenia „Widok – Cieniowanie pól” lub wykorzystanie skrótu klawiaturowego „CTRL+F8”. Wszystkie treści będące w rzeczywistości polem, zostaną zacieniowane, przy czym zacieniowanie dotyczy wyłącznie postaci dokumentu na ekranie.
Niezależnie od cieniowania pól, Writer umożliwia wyświetlenie nazw pól wykorzystanych w dokumencie. Opcję tę włącza lub wyłącza polecenie „Widok – Nazwy pól” lub skrót klawiaturowy „CTRL+F9”. W przypadku pól listu seryjnego ujawnioną nazwą pola będzie nazwa złożona z nazwy bazy danych, nazwy tabeli i nazwy pola w rekordzie, rozdzielonych kropką.
Kolejnym elementem redagującym dokument, to takie jego dopracowanie, aby w zależności od płci dziecka, nad imieniem i nazwiskiem ucznia pojawił się napis „Uczeń” albo „Uczennica”, zaś w treści zawiadomienia po słowie „że” pojawiło się słowo „syn” lub „córka” a po słowie „półroczu” słowo „uzyskał” lub „uzyskała”. Oczywistym jest, że słowa te zależą od płci dziecka i dlatego właśnie w źródle znajduje się pole „płeć”, sygnalizujące literą „K” lub „M” płeć osoby.
Writer umożliwia wstawianie do dokumentu pól różnych kategorii i to właśnie położenie tych innych pól, zaznaczyłem zielonymi prostokątami. Te pozostałe pola, nie są związane z tworzeniem korespondencji seryjnej. Polem niezbędnym w tym przypadku jest pole „Tekstu warunkowego”. Pole to wstawić można wykorzystując wspomniane już polecenia „Wstaw – Pola – Inne…” albo skrót klawiaturowy „CTRL+F2”.

Pole „Tekst warunkowy” znajduje się w kategorii „Funkcje”. Pole umieści w dokumencie jeden z dwóch podanych tekstów, w zależności od spełnienia, bądź niespełnienia warunku zdefiniowanego w tym polu. W ramce „Warunek” należy wpisać wyrażenie logiczne. Jeśli wartością tego wyrażenia logicznego będzie TRUE (prawda), w dokumencie pojawi się tekst wprowadzony do ramki „Wtedy”, jeśli wartością tego wyrażenia będzie FALSE (nieprawda) wówczas w dokumencie pojawi się tekst wprowadzony do ramki „W przeciwnym przypadku”. Budując takie pole nie należy kierować się wielkością ramki przeznaczonej na teksty. Można wprowadzić wielolinijkowe teksty i długie i złożone wyrażenie logiczne.
O wyrażeniach logicznych można przeczytać w opracowaniu poświęconym obliczeniom w Writerze (zob. „Obliczenia w programie Writer”). Tutaj wspomnę tylko, że badanie czy coś jest równe czemuś, wymaga użycia operatora „==”, dwóch napisanych po sobie znaków równości. Konstruując wyrażenie logiczne trzeba znać nazwy używanych pól, stąd – dla wygody – widoczne źródło danych. Używanie w wyrażeniu logicznym stałych tekstowych wymaga ujęcia ich w cudzysłowy. Na rys. 18 wskazałem miejsce, w którym pojawia się przemiennie słowo „Uczennica” lub „Uczeń” już po wstawieniu pola „Tekst warunkowy”. Wyświetlony jest tam tekst „Uczennica”, bowiem w wybranym rekordzie źródła danych, w polu „płeć”, wpisana jest litera „K”. Jeszcze jedna dygresja. Porównując pola tekstowe należy uwzględniać wszystkie występujące w takim polu znaki. Uważny czytelnik zauważył być może, że pole „płeć” w źródle zawiera tak naprawdę najpierw spację a dopiero po niej stosowną literę. Dlatego warunek został zapisany jako „płeć==" K"”. Gdybym go wpisał bez poprzedzającej literę „K” spacji, to taki warunek nigdy nie byłby spełniony, więc w każdym dokumencie pojawiłby się tekst „Uczeń”.
Dokładnie w ten sam sposób umieściłem tekst warunkowy wstawiający odpowiednio słowa „córka” lub „syn” i słowa „otrzymał” lub „otrzymała”.
Dokument wyjściowy uzupełniony zostanie jeszcze o dwa dodatkowe pola. Pierwszym będzie pole wstawiające do dokumentu datę. Datę można oczywiście wpisywać każdorazowo ręcznie, tutaj jednak wykorzystam pole programu Writer. Pole to, umieszczone w dokumencie, wprowadzi do niego datę pobraną z komputera.
Po ustawieniu kursora tekstowego w wymaganym miejscu, wywołuję polecenia „Wstaw – Pola – Data”. Do dokumentu wstawiona zostanie bieżąca data. Jeśli sposób prezentacji daty ma być inny niż ten, który został zastosowany, należy kliknąć dwukrotnie w to wstawione pole daty. Wynikiem będzie otwarcie okna dialogowego edycji pola, pozwalającego ustalić inne właściwości pola. Okno to przedstawia rys. 19.

W sekcji „Wybierz” tego otwartego okna znajdują się dwie opcje do wyboru. Opcja „Data (stała)” oznacza wstawienie daty jako niezmieniającego się napisu wynikającego z dnia, w którym pole zostało utworzone. Opcja „Data” oznacza, że pole będzie aktualizowane każdorazowo przy otwieraniu dokumentu. Jego treść będzie zatem zależała od rzeczywistej daty kiedy dokument został otwarty. Sekcja „Format” w oczywisty sposób sygnalizuje możliwości wyboru sposobu prezentacji daty. W końcu pole „Przesunięcie (dni)” spowoduje wstawienie daty wcześniejszej, gdy podana liczba jest liczbą ujemną, lub późniejszej – o podaną liczbę dni. Po ustaleniu potrzebnych opcji zatwierdza się je przyciskiem „OK”.
Widoczne w oknie dialogowym dwa trójkątne przyciski uaktywnią się, gdy w dokumencie wystąpią co najmniej dwa pola tego samego typu. Pozwalają one na przechodzenie między polami i ustalanie ich opcji. Pole daty można także wstawić poprzez wybór okna dialogowego „Pola” przywoływanego skrótem klawiaturowym CTRL+F2 lub poleceniem „Wstaw – Pola – Inne…”. Pole to znajduje się w kategorii „Dokument”.
Drugim polem które chciałbym wykorzystać, to pole pozwalające ustalić nazwisko wychowawcy. Przydatne byłoby ono, gdyby tego samego dokumentu wyjściowego używali różni nauczyciele. Takim polem jest „Pole wprowadzania” znajdujące się w kategorii „Funkcje”. Dla tego pola wystarczy w ramce „Odwołanie” określić wpis wyjaśniający jakiego rodzaju dane mają zostać wprowadzone.

Na powyższej ilustracji, dla tworzonego „Pola wprowadzania” zdefiniowano treść w ramce „Odwołanie” a wstawienie go ma nastąpić do zaznaczonego miejsca w dokumencie. Po wykonaniu polecenia „Wstaw” zostanie wyświetlone kolejne okno dialogowe, takie jak poniżej.

Jak widać treść odwołania pojawia się w części informacyjnej tego okna wyjaśniając co ma zostać wprowadzone. Po wpisaniu właściwych danych i zatwierdzeniu ich przyciskiem „OK”, można zamknąć okno dialogowe „Pola”. [Zmiany z dn. 11.12.2016]Od tego też momentu, każdorazowe kliknięcie myszką w pole wyświetlające nazwisko, otworzy ponownie okienko pokazane na rys. 21, pozwalając zmienić jego zawartość. Nikt z czytelników nie sygnalizował niezgodności w działaniu tego pola. Zorientowałem się dopiero przy wersjach 5.1.6 (LibreOffice) i 4.1.3 (Apache OpenOffice). Oto zmiany. Po naprowadzeniu wskaźnika myszki na obszar pola a także jego kliknięciu, pojawi się „dymek” zawierający tekst objaśniający, ten wpisany do ramki „Odwołanie”. Aby zmienić treść reprezentowaną przez to pole wprowadzania należy w nie kliknąć myszką. Spowoduje to zaznaczenie pola i w tym stanie można zacząć pisać nową jego zawartość. Jeśli kliknie się ponownie wewnątrz już zaznaczonego pola, kursor tekstowy ustawi się na wskazanym miejscu i można modyfikować tekst, tak jak inne teksty w dokumencie. W tym trybie współpracy z polem można niechcący usunąć pole z dokumentu, np. naciskając nieuważnie klawisz DELETE. Jeśli w dokumencie wstawiono „Pole wprowadzania”, lub więcej takich pól, to wprowadzenie nowej wartości można dokonać, bez wskazywania położenia pól, skrótem klawiaturowym „CTRL+SHIFT+F9”. Skrót inicjuje wprowadzanie nowych wartości do wszystkich pól wprowadzania po kolei. Tylko wtedy gdy aktywacja pola spowodowana jest działaniem skrótu klawiaturowego pojawi się ponownie okno dialogowe, takie jak to widoczne na rys. 21. Gdyby pole miało być przeredagowane, gdyż chcemy zmienić treść objaśniającą to pole, to należy ustawić kursor tekstowy bezpośrednio przed polem i wywołać polecenia „Edycja – Pola…” albo dwukrotnie kliknąć w obszar pola. [Koniec zmian]
[Zmiany z dn. 18.08.2018]Kolejne zmiany pojawiły się w LibreOffice wersji 6.0.6 (a przynajmniej dopiero je zauważyłem). Dotyczą pola wprowadzania. Obecnie dwukrotne kliknięcie tego pola jest równoznaczne z użyciem skrótu klawiaturowego „CTRL+SHIFT+F9”. Otwiera się okno dialogowe, o nieco innym układzie niż to pokazane na rys. 21., związane z klikniętym polem. Przyciski „Wstecz” i „Dalej” pozwalają przejść do kolejnych pól wprowadzania występujących w dokumencie. Nowy wygląd tego okna dialogowego przedstawia rys. 21a.[Koniec zmian]

W tym miejscu już niejako z rozpędu, wspomnę o innym polu, pozwalającym wybrać potrzebną informację z listy możliwości. To pole to „Lista wprowadzania” także znajdujące się w kategorii „Funkcje”. Przy pomocy ramki „Element” okna definiującego to pole, można utworzyć listę elementów do wyboru. W omawianym przez nas przykładzie, mogłyby to być nazwiska wszystkich nauczycieli. Pole tego typu wstawione do dokumentu, pozwala tylko wybrać jedną z proponowanych pozycji, nie można za jego pomocą dodać nowej treści.
Z „technicznego” przygotowania dokumentu wyjściowego pozostało jeszcze obliczenie średniej. Aby to zrobić, wystarczy do komórki tabeli przeznaczonej na wynikową liczbę wpisać formułę „=mean<b1:b7>”, zgodnie z zasadami tworzenia formuł. (zob wspomniane już opracowanie o obliczeniach w Writerze).
Zanim zredaguję dokument do końcowej – przeznaczonej do emisji – postaci, pokażę go z ujawnionymi nazwami pól. Aby ułatwić ich lokalizację są one zacieniowane. [Zmiana z dn. 11.12.2016] Tutaj także nowe wersje Writera wprowadziły zmiany. „Pole wprowadzania” kategorii „Funkcje” nie jest w tym widoku ujawniane. Na ilustracji widać tekst „Pole wprowadzania”, w obecnych wersjach zawsze wyświetlana tam jest ostatnio wprowadzona wartość tego pola, w przypadku tego przykładu – nazwisko wychowawcy. [Koniec zmian]

Kończąc redagowanie dokumentu ustalę w treści różne kroje i odmianę fontów oraz ich wielkość. W tabelce ukryję wszystkie pionowe krawędzie w ostatnim wierszu oraz dolną krawędź w tym wierszu. Ostatecznym wynikiem takiego dokumentu będzie więc np. postać jak poniżej.

Tak przygotowany dokument wyjściowy można już zapisać do wykorzystywania przez nauczycieli.
Emisja dokumentów seryjnych.
Gotowy dokument wyjściowy można otworzyć w dowolnym momencie i wyemitować na jego podstawie wszystkie lub wybrane listy seryjne.
Tutaj działanie jest bardzo proste, wystarczy po prostu rozpocząć drukowanie. Procedury Writera wykryją, że przeznaczony do drukowania dokument zawiera pola z bazy danych, i wyświetlą prośbę o podjęcie decyzji o sposobie drukowania.

Przycisk „Nie” oznacza, że wydrukowany ma być tylko dokument wyjściowy. Przycisk „Tak” spowoduje przejście do drugiego etapu definiowania wydruku seryjnego i wyświetli kolejne okno dialogowe.

To złożone okno dialogowe, w górnej części, zawiera widok źródła, znany już z prac nad dokumentem wyjściowym. Ta część okna posłuży do wyselekcjonowania rekordów przeznaczonych do wyemitowania dokumentów korespondencji seryjnej i określenia kolejności drukowania.
Sekcja „Rekordy” pozwala wskazać, które rekordy z tych wyselekcjonowanych, lub wszystkich, jeśli selekcja nie była przeprowadzona, mają zostać wydrukowane. Nazwy opcji mówią same za siebie. Liczby „Od” i „Do” są numerami rekordów w wyselekcjonowanym zbiorze. Zaznaczenie rekordu polega na kliknięciu w wybrany rekord w obszarze, w którym widoczna jest zielona strzałka. Zaznaczanie kolejnych rekordów realizowane może być z użyciem klawisza SHIFT lub CTRL, zgodnie z ogólnymi zasadami zaznaczania. Na ilustracji opcja „Zaznaczone rekordy” jest niedostępna, bo żaden rekord nie został zaznaczony.
W sekcji „Wyjście” podejmowana jest decyzja o natychmiastowym wydruku (opcja „Drukarka”) lub zapisaniu wynikowej korespondencji seryjnej w postaci pliku (opcja „Plik”). Żadna z opcji zapisywania do pliku nie jest dostępna jeśli zaznaczono opcję „Drukarka”.
Jeśli jednak wybrano „Plik”, to pierwszym wyborem jest decyzja czy powstać ma jeden plik, zawierający kolejne dokumenty seryjne jako osobne strony, czy też dla każdego dokumentu seryjnego ma powstać oddzielny plik.
Wybór zapisu jako jednego dokumentu spowoduje, że system, w standardowym oknie dialogowym, poprosi o nazwę pliku, wskazanie lokalizacji oraz wybranie, jeśli to konieczne, typu zapisywanego pliku. Taki plik należy traktować jak normalny wielostronicowy dokument, więc można go otworzyć do edycji i dokonywać w nim dalszych poprawek lub uzupełnień albo po przegraniu na przenośny nośnik wydrukować w innym miejscu.
Podobnie zachowa się system, gdy wybrany zostanie wariant „Zapisz jako indywidualny dokument” ale nie będzie zaznaczonej opcji „Generuj nazwę pliku z Bazy danych”. Tu także należy podać nazwę pliku, lokalizację i typ. Podana nazwa pliku zostanie wykorzystana do utworzenia wszystkich plików w ten sposób, że będzie uzupełniona o kolejny numer tworzonego pliku. Pierwszy utworzony plik ma numer 0 (zero).
W końcu wariant ostatni, gdy zaznaczona zostanie opcja „Generuj nazwę pliku z Bazy danych”. Tutaj w kolejnych rozwijanych polach należy wskazać, które pole bazy danych ma zostać użyte do utworzenia nazwy pliku („Pole”), w jakiej lokalizacji mają znaleźć się poszczególne pliki („Ścieżka”) i jaki ma być format generowanych plików („Format pliku”). Powstające pliki otrzymają nazwy zgodne z treścią pól, na ilustracji widać, że proponowane byłoby pole „Nazwisko”. Nazwy te także mają dopisane kolejne numery, pierwszym numerem jest 0 (zero). Jeśli trafi się w źródle inna osoba o takim samym nazwisku, plik otrzyma nazwę z kolejnym numerem.
Omówię teraz selekcjonowanie rekordów. Gdy organizowana jest wywiadówka, wychowawca musi wydrukować korespondencję dotyczącą swoich podopiecznych. Musi zatem z całego źródła wybrać swoich uczniów. Ponadto może chcieć wydrukować korespondencję w określonym porządku.
Na rysunku 25. ostatnia ikonka, po prawej stronie, pozwala wyłączyć lewą część widoku źródła, czyli wykaz zarejestrowanych baz. Takie zmodyfikowane okno źródła przedstawia rysunek poniżej.

Na powyższej ilustracji czerwony prostokąt otacza ikony poleceń związanych z selekcją rekordów a zielony – ikony związane z ich uporządkowaniem.
Z czterech ikon w czerwonym prostokącie tylko dwie są na ilustracji dostępne. Służą one do definiowania warunków selekcji a ponieważ żadne warunki nie zostały jeszcze określone, dwie pozostałe ikony są niedostępne.
Pierwsza z lewej w tym obszarze, to ikona opisana jako „AutoFiltr”. Pozwala ona wyselekcjonować rekordy, które w określonym polu zawierają konkretną wskazaną wartość. Dla przykładu, jeśli chcemy wybrać uczniów tylko z 4 klasy, przewijamy rekordy tak aby znaleźć pierwszy, który w polu „Klasa” ma wpisaną czwórkę. Klikamy pole z wybraną wartością w znalezionym rekordzie a następnie w ikonkę „AutoFiltr”. W widoku źródła pozostaną teraz tylko rekordy, które pasują do tego filtra. By dalej ograniczyć liczebność rekordów, np. tylko do uczniów z oddziału „b”, odnajdujemy pierwszy rekord z takim właśnie wpisem w polu „gr”, klikamy wybraną wartość w tym polu, i ponownie wybieramy ikonkę „AutoFiltr”. Teraz źródło danych zawiera tylko rekordy uczniów klasy 4b. Wykorzystanie autofiltra pozwala wyselekcjonować rekordy wg kilku pól połączonych operatorem logicznym „I” czyli takie, które pasują do każdego filtra.
Już ustawienie pierwszego filtru uaktywnia drugą w tym obszarze ikonkę, opisaną jako „Zastosuj filtr”. Jej kliknięcie na przemian włącza lub wyłącza ustawione filtry. Widać zatem tylko wyselekcjonowane rekordy albo wszystkie.
Kolejna ikonka opisana jest jako „Filtr standardowy” i pozwala zbudować bardziej złożone wyrażenia selekcjonujące rekordy. Służy do tego specjalnie otwierane okno „Filtr standardowy”.

Jak widać filtr może powiązać trzy wybrane pola łącząc ustalone relacje operatorem „LUB” oraz „I”. Filtr standardowy rozpoznaje rodzaj pól i dla pól tekstowych pozwala wybrać warunek „jak” odpowiadający temu, że zawartość pola ma być dopasowana do tego co wpisano do pola „Wartość”, „nie jak” – oznaczającym, że wybrane mają być rekordy, które nie pasują do wpisanej wartości. Ponadto jako warunek może zostać wybrany „puste” albo „niepuste” mówiący, że wybrane mają być te rekordy, które nie zawierają żadnego wpisu w wybranym polu, albo przeciwnie, takie które mają jakiś, choćby dowolny, wpis. Napisałem o dopasowaniu bądź niedopasowaniu do wartości, gdyż przy dwóch pierwszych warunkach, we wpisywanych wartościach można użyć znaków zastępczych. Znak zapytania (?) oznacza jakiś dowolny jeden znak w dopasowywanej treści a gwiazdka (*) dowolne znaki, zero lub więcej. Zatem zapis dla pola „Imię”, widocznego na rysunku, wartości „?an*”, przy wybranym warunku „jak”, oznacza znalezienie wszystkich rekordów, w których imię pasuje do wzorca określającego drugą i trzecią literę imienia na „an”. W tym omawianym przykładzie wyselekcjonowane zostaną cztery rekordy z imionami: Jan, Wanda, Hanna i Janina gdyż tylko one pasują do wzorca.
Jeśli pole zostanie zinterpretowane jako numeryczne, pole warunku pozwoli określić jedną z relacji widocznych na rysunku. W tym wykazie warunków, na ostatniej pozycji także znajdują się pozycje „puste” i „niepuste”.
Czwarta ikonka z rysunku 26. opisana jest jako „Usuń filtr/sortowanie” i pozwala usunąć wszystkie zastosowane filtry i sortowania, przywracając „stan zerowy” źródła. Ikonka ta jest aktywna, jeśli aktywny jest jakiś filtr lub rekordy zostały posortowane.
Rekordy źródła – wszystkie albo wyselekcjonowane – mogą zostać posortowane, i w takim porządku wydrukowane albo zapisane w pliku, jeśli zapis następuje do jednego pliku. Na rys. 26. zielonym prostokątem otoczyłem trzy ikony pozwalające posortować rekordy źródła. Za najprostsze sortowanie odpowiadają dwie ostatnie ikony, opisane odpowiednio jako „Sortuj rosnąco” i „Sortuj malejąco”. Wystarczy kliknąć w wybraną nazwę pola, lub dowolną wartość w polu, które decyduje o porządku sortowania a następnie użyć jednej z wymienionych ikonek. Jeśli wymagane jest sortowanie wielopoziomowe, trzeba skorzystać z pierwszej ikonki opisanej jako „Sortuj”. Spowoduje ona otwarcie okna dialogowego „Porządek sortowania”.

Można tu zdefiniować do trzech kluczy sortowania, wybierając dla każdego z nich porządek sortowania. Parametry ustalone na przedstawionej ilustracji ułożą rekordy źródła wg klas, w kolejności malejącej, Takie same klasy będą ułożone wg liter, w kolejności rosnącej a uczniowie w klasach będą ułożeni według nazwisk w kolejności, którą jeszcze można wybrać z rozwijanej listy.
Tak spreparowane źródło danych będzie podstawą do wyemitowania korespondencji seryjnej. To wśród tych wyselekcjonowanych rekordów można jeszcze dodatkowo wybrać rekordy tworzące korespondencję seryjną wykorzystując sekcję „Rekordy” widoczną na rys. 25. Zatwierdzenie ustalonych parametrów przyciskiem „OK” rozpocznie proces emisji.
To jest pierwszy ze sposobów zrealizowania korespondencji seryjnej.
Korespondencja seryjna - Kreator.
Sposób drugi, to wykonywanie kolejnych działań w krokach generowanych przez procedurę tworzenia korespondencji seryjnej. Procedurę tę uruchamia polecenie „Narzędzia – Kreator korespondencji seryjnej…” otwierając okno pokazane na poniższym rysunku.

Okno to proponuje osiem kroków postępowania ale nie wszystkie z nich muszą zostać wykonane. Ilustracja powyżej pokazuje rolę pierwszego kroku. Pozwala on wybrać dokument wyjściowy. Znaczenie dostępnych opcji jest jednoznacznie zrozumiałe.
Krok drugi dotyczy wyboru typu dokumentu.

Określa mianowicie czy dokument wyjściowy zostanie wykorzystany do wyemitowania zwykłych listów seryjnych (drukowanych lub zapisanych w pliku) czy do utworzenia wiadomości elektronicznych. Wybór typu dokumentu w tym kroku nie ma jednak znaczenia wyboru ostatecznego.
Krok trzeci pozwala dodać do dokumentu tak zwany blok adresowy. Znaczna część korespondencji seryjnej to pisma o stałej treści lecz adresowane do różnych osób. Omówione we wcześniejszej części tego opracowania zasady wstawiania pól listu seryjnego, mogą zostać wykorzystane do samodzielnego utworzenia początkowej treści listu zawierającego adres i krok ten nie byłby potrzebny. Można też wykorzystując źródło danych wstawić do dokumentu blok adresowy bez umieszczania indywidualnych pól.

Blok adresowy bazuje na zdefiniowanych w programie Writer pewnych umownych nazwach pól i definiowany jest wewnątrz prostokątnej ramki zgodnie z przyjętym schematem. Na potrzeby opisania tego kroku, zaznaczyłem opcję „Ten dokument powinien zawierać blok adresowy”, gdyż tylko wtedy aktywne będą inne możliwości ustawień. Na ilustracji, pod zaznaczoną opcją, widoczne są dwa schematy rozmieszczania informacji w bloku adresowym. Pierwszy zawiera tylko imię i nazwisko (i ten jest zaznaczony), drugi – jest bardziej rozbudowany. Jeśli żaden z tych schematów nie jest odpowiedni, można kliknąć znajdujący się obok przycisk „Więcej…”. Otworzy on dodatkowe okno, takie jak na rys. 32.

W oknie tym można wybrać inny schemat. Można też utworzyć nowy schemat, zmodyfikować istniejący albo usunąć zbędny.
Jeśli w źródle danych nazwa pola będzie zgodna z jakąś wewnętrzną umowną nazwą Writera to pole to zostanie zaakceptowane w bloku adresowym. W moim źródle danych znajdują się pola „Imię” i „Nazwisko”, więc zostały od razu zaakceptowane w bloku adresowym, gdyż wśród umownych pól Writera takie nazwy pól są wykorzystane. Widać to w podglądzie dopasowania pól na rys. 31. Jeśli w źródle danych informacje adresowe zawarte są w polach o nazwach innych niż te umowne, należy dopasować nazwy do siebie. Np. użytkownik, pole zawierające nazwę miejscowości nazwał „Miasto”. Blok adresowy wymaga pola o umownej nazwie „Miejscowość”. Aby prawidłowo interpretować nazwy miejscowości należy więc dopasować do umownej nazwy „Miejscowość” rzeczywistą nazwę „Miasto”. Służy temu przycisk „Dopasuj pola”.

W otwartym oknie dla każdej nazwy umownej znajdującej się po lewej stronie należy dopasować pole z własnego źródła, wybierając je z rozwijanej listy nazw pól. Nie ma obowiązku dopasowywania wszystkich pól. Nie można jednak zastosować wybranego schematu bloku adresowego, jeśli choćby jedno pole tego schematu nie ma dopasowania. Nie można bowiem zakończyć kroku trzeciego i żaden z następnych kroków nie jest dostępny.
Jeśli blok adresowy nie jest potrzebny nie należy zaznaczać opcji „Ten dokument powinien zawierać blok adresowy”.
Krok czwarty pozwala zdefiniować zwrot grzecznościowy.

Krok ten należy dopracować jeśli w powyższym oknie zaznaczona została opcja „Ten dokument powinien zawierać zwrot grzecznościowy”. Można zdecydować czy zastosowany ma być ogólny czy indywidualny zwrot grzecznościowy. Jeśli zastosowany ma być indywidualny zwrot grzecznościowy to można go zróżnicować w zależności od płci osoby, do której jest skierowany. Przyciski „Nowy…” pozwalają utworzyć własne zwroty grzecznościowe, odrębnie dla kobiety i mężczyzny. Inne opcje tego obszaru nie wymagają szczegółowych wyjaśnień. Zwrot grzecznościowy także wykorzystuje umowne pola, o których napisałem przy bloku adresowym, dlatego także w tym kroku można wskazać dopasowanie pól własnej bazy danych do pól umownych programu Writer.
Krok piąty to dopasowanie położenia bloku adresowego i zwrotu grzecznościowego w tworzonym dokumencie. Krok ten będzie dostępny tylko wówczas, gdy do dokumentu dodany będzie blok adresowy lub zwrot grzecznościowy. Okno tego kroku poniżej.

Blok adresowy można przemieszczać w górę i w dół aby ulokować go w wybranym miejscu. Możliwość przemieszczania w lewo i w prawo zależy od tego czy zaznaczona została opcja „Wyrównaj do treści tekstu”. Zwrot grzecznościowy można przesuwać tylko w górę lub w dół. Po prawej stronie okna, na podglądzie, można sprawdzić położenie tych elementów. Jeśli podgląd jest za mało szczegółowy, można zmienić stopień powiększenia.
Krok szósty pozwala przejść do edycji dokumentu, bez przerywania działania kreatora korespondencji seryjnej. Okno tego kroku ukazuje rys. 36.

Krok ten ma dodatkową bardzo przydatną właściwość. Pozwala oglądać zawartość dokumentu wyjściowego dla różnych rekordów źródła, bez omawianego wcześniej zaznaczania rekordu w źródle i wybierania ikonki „Dane na pola”. Przyciski pozwalają przejść do pierwszego lub ostatniego rekordu, lub przechodzić po jednym rekordzie w przód lub w tył w źródle. Można też wpisać numer konkretnego rekordu w okienku numeru rekordu i nacisnąć klawisz ENTER. Jeśli autor opracowuje dokument zgodnie z wcześniej omówionym sposobem, to i tak może wywołać kreatora, przejść od razu do kroku szóstego i podejrzeć zachowanie się dokumentu w zależności od różnych rekordów. Aby przejść do edycji dokumentu należy nacisnąć widoczny w oknie przycisk „Edycja dokumentu…”.
Siódmy krok, to personalizowanie dokumentów. Po wyborze tego kroku kreator przystąpi do wygenerowania indywidualnych dokumentów seryjnych, zawartych w wielostronicowym, nowym dokumencie. Tutaj trzeba wiedzieć, że na ten krok nie ma wpływu wyselekcjonowanie rekordów. Personalizowane są wszystkie rekordy tabeli. Najpierw pojawi się okienko informujące o tworzeniu dokumentu, takie jak na rysunku poniżej.

Po czym na tle tego nowoutworzonego dokumentu pojawi się właściwa plansza kroku siódmego. Pozwala ona na dodatkowe edytowanie nowopowstałego dokumentu, bez przerwania pracy kreatora.
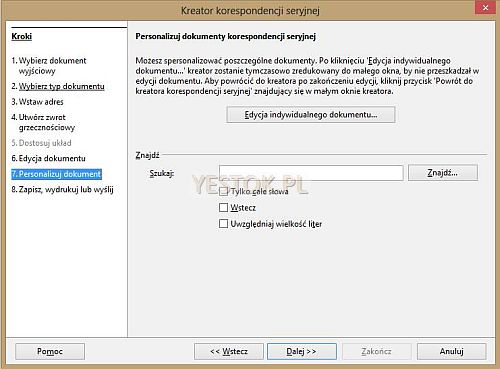
W sekcji „Znajdź” tej planszy, można podać kryteria wyszukania informacji w całym dokumencie i od razu do niej przejść. Można też przejść do edycji całego dokumentu, w taki sam sposób jak to było możliwe w kroku szóstym.
Ostatni, ósmy krok kreatora pozwala wykonać kilka różnych działań, i w zależności od wybranych, pojawią się różne opcje. Podstawowe okno tego kroku przedstawia rys. 39.

Opcje „Zapisz dokument wyjściowy”, „Zapisz dokumenty wynikowe” i „Drukuj dokumenty wynikowe” odpowiadają podobnym opcjom omówionym już poprzednio, kiedy pisałem o drukowaniu dokumentu. Na uwagę zasługuje tu ostatnia opcja „Wyślij dokumenty wynikowe jako e-mail”. Jej wybór wyświetli dodatkowe pola wymagające wypełnienia. Pola te przedstawiam na rys. 40.

Rozwijana lista nazw pól źródła danych przy pozycji „Do”, wymaga wskazania tego pola w źródle, które zawiera adres mailowy. Widoczny obok przycisk „Kopiuj do…” powinien raczej nazywać się „Kopia do…” bowiem otwiera okno dialogowe pozwalające podać adresy mailowe nazywane „Do wiadomości” oraz „Do utajnionej wiadomości”.
W pozycji „Temat” powinien zostać wpisany temat korespondencji. Jest dobrym obyczajem aby każdy wysyłany mail miał wpisany temat, krótko wyjaśniający czego dotyczy przesyłana korespondencja.
Pozycja „Wyślij jako” pozwala wybrać jak ma zostać potraktowany wysyłany dokument. Widoczny na ilustracji wpis „Komunikat HTML” lub znajdujący się na liście „Zwykły tekst” oznacza włączenie treści dokumentu bezpośrednio do e-maila. Pozostałe możliwości, to „Dokument tekstowy Open Dokument”, „Dokument PDF programu Adobe” lub „Dokument Microsoft Word”. Takie dokumenty są wysyłane jako załączniki do wysyłanego maila, dlatego przy wybraniu jednego z nich uaktywni się przycisk „Właściwości…” pozwalający zredagować główną treść listu.
Gdy dokument seryjny wysyłany jest jako załącznik można określić jego nazwę, w pozycji „Nazwa załącznika”. Pozostałe widoczne opcje nie wymagają jak sądzę opisu.
Wysyłanie korespondencji seryjnej przez pocztę elektroniczną jest realizowane bezpośrednio przez program Writer, pod warunkiem że użytkownik ma już funkcjonujące konto pocztowe no i oczywiście dostęp do Internetu. W programie edytora należy ustawić parametry konta pocztowego wykorzystywanego do wysyłania korespondencji. Jeśli nie były one jeszcze zdefiniowane, system zapyta czy ma je zdefiniować teraz.
Jest jednak i niedogodność korzystania z tego sposobu kreowania korespondencji seryjnej, mianowicie kreator nie daje możliwości selekcji rekordów w taki sposób jak było to możliwe przy wyborze drukowania. Kreator realizuje emisję dla wszystkich rekordów bez względu na to czy rekordy zostały wyselekcjonowane. Namiastką selekcji jest możliwość wyeliminowania wybranych rekordów przez zaznaczenie opcji „Wyłącz tego odbiorcę” w szóstym kroku kreatora. Trzeba to jednak robić „ręcznie” dla każdego rekordu indywidualnie. Z kolei, tylko korzystanie z kreatora umożliwia wysyłanie korespondencji jako poczty elektronicznej.
Drukowanie kopert.
Z przygotowaniem korespondencji może być także związane przygotowanie koperty. Jeśli tworzony jest jednostkowy dokument, powstaje dla niego jedna dedykowana koperta. Gdy mamy do czynienia z korespondencją seryjną, koperty mogą być przygotowanie do każdego indywidualnego dokumentu. Za tę funkcjonalność odpowiada polecenie „Wstaw – Koperta…”. Polecenie to pozwala, po przygotowaniu koperty, zadecydować czy zredagowana koperta ma zostać dołączona do dokumentu jako jego pierwsza strona, czy też ma wytworzyć nowy dokument odpowiadający kopercie. W pierwszym przypadku, jako pierwsza strona dokumentu drukowana będzie koperta a dopiero potem strony właściwego dokumentu. Jeśli dysponujemy drukarką, w której można ustalić, że pierwsza drukowana strona pobiera papierowy nośnik z innego podajnika niż pozostałe drukowane strony, możemy wydrukować korespondencję z poprzedzającą ją zaadresowaną kopertą. Drugi przypadek pozwala utworzyć dokument odpowiadający kopercie i wydrukować ją lub je, jeśli utworzymy na bazie koperty korespondencję seryjną, jako oddzielne dokumenty. Wywołanie polecenia otworzy rozbudowane trójzakładkowe okno, ustalające treść zamieszczoną na kopercie i jej wygląd.

Pierwsza zakładka okna – „Koperta” – pozwala ustalić treści umieszczane na kopercie. Na kopercie wyróżnia się dwa obszary. Obszar odbiorcy i obszar nadawcy a ich położenie na kopercie sygnalizują szare prostokąty. Jeśli koperta ma zostać zaadresowana do konkretnej osoby, wystarczy w obszarze odbiorcy wpisać wprost wymagany adres. Jeśli jednak koperta ma być adresowana do kolejnych odbiorców, tak jak w korespondencji seryjnej, trzeba określić bazę danych i tabelę, zawierającą wymagane źródło danych. W rozwijanej liście „Pole bazy danych” należy wybrać te pola, których zawartość ma się znaleźć na kopercie, przenosząc je do obszaru odbiorcy przyciskiem czarnej strzałki. Rysunek przedstawia sytuację gdy wstawiono już pole „Imię”. Drugi obszar, czyli obszar nadawcy, można określić gdy w zakładce zaznaczono opcję „Nadawca”. Bezpośrednio po zaznaczeniu tej opcji, do obszaru nadawcy wpisywane są dane zamieszczone w opcjach pakietu (x)Office („Narzędzia – Opcje… – (x)Office – Dane użytkownika”). Można ten wstawiony wpis przeredagować na dowolny adres nadawcy.

Druga zakładka – „Format” – Pozwala zdefiniować format obszaru odbiorcy i nadawcy. Pozycja „od lewej” określa położenie obszaru od lewej krawędzi koperty. Pozycja „od góry” określa to położenie od górnej krawędzi koperty. Każdy z obszarów ma swój własny przycisk „Edycja”. Przycisk ten pozwala przypisać atrybuty czcionek albo akapitów tekstom w odpowiadających obszarach. Wybrane atrybuty dotyczą wszystkich wpisów w obszarze. Ostatnia sekcja tej zakładki, „Rozmiar”, pozwala ustalić rozmiar koperty. Rodzaj koperty można wybrać z rozwijanej listy formatów albo wpisać wymiary koperty jeżeli potrzebnego formatu nie ma na liście.

Ostatnia zakładka – „Drukarka” – ustala sposób podawania koperty w drukarce.
Kiedy wszystkie elementy dotyczące koperty zostaną ustalone, można wybrać przycisk „Wstaw”, który spowoduje dodanie do dokumentu pierwszej strony o wymiarach koperty. Wybór przycisku „Nowy dokument” utworzy jednostronicowy dokument o wymiarach koperty i pozwoli drukować same koperty.
W tych utworzonych dokumentach można, jak w każdym dokumencie, sformatować wybrane fragmenty koperty dodatkowo wg własnego uznania.
Jeśli na kopercie znajdują się pola pobierane ze źródła danych, to dalsze postępowanie, czyli emisja, jest analogiczne do drukowania dokumentów korespondencji seryjnej.
Drukowanie etykiet.
Etykiety to niewielkie arkusiki papieru, obecnie zazwyczaj z samoprzylepnym podłożem, które po zadrukowaniu można umieszczać na wybranych przedmiotach, np. towarach, kopertach, paczkach, indeksach studenckich itp. Technologicznie umieszczone są albo na podkładzie ciągłym, albo na kanwie arkusza, na którym umieszczone są w rzędach i kolumnach. Zdecydowana większość drukarek w powszechnym stosowaniu, to drukarki arkuszowe, wobec czego tego typu etykiety są najczęściej wykorzystywane. Etykiety arkuszowe umieszczone są na znormalizowanym arkuszu, najczęściej o formacie A4 (chociaż nie musi to być regułą), a od ich wymiarów zależy w ilu wierszach i kolumnach są rozmieszczone. Etykiety w zależności od producenta mają także znormalizowaną nomenklaturę. Przygotowanie etykiet, w odróżnieniu od kopert, jest zawsze niezależnym procesem edycyjnym, i realizowane jest poprzez wywołanie poleceń „Plik – Nowy – Etykiety”.
Otwarte zostanie okno dialogowe pozwalające ustalić parametry etykiet. Okno ma trzy zakładki, pierwsza ma taką sama nazwę jak nazwa okna, czyli „Etykiety”.

Obszar „Tekst etykiety” przeznaczony jest na jej treść. Jeśli zostanie zaznaczona opcja „Adres” widoczna powyżej tego obszaru, to jako treść zostaną umieszczone dane pobrane z danych użytkownika, tak jak to już omawiałem w przypadku kopert.
Jeśli wszystkie etykiety mają wyglądać tak samo, można wpisać własną treść. Np. nazwę towaru, wagę i cenę. Jeżeli etykiety mają zawierać dane pobierane ze źródła danych, to należy określić bazę danych i tabelę źródła a następnie, z rozwijanej listy „Pole bazy danych” wybrać pola, które mają znajdować się na etykiecie i przenieść je do niej, za pomocą przycisku z czarną strzałką. Na ilustracji widać, że na etykietach powinny pojawić się imiona i nazwiska pobierane z bazy, o której była już mowa w tym opracowaniu.
W sekcji „Format” tej zakładki definiowane są techniczne aspekty etykiety. Wykluczające się wzajemnie opcje „Ciągły” i „Arkusz” określają rodzaj nośnika na jakim znajdują się etykiety. Rozwijana lista „Marka” pozwala wybrać firmę – producenta etykiet, a lista „Typ” wybrać konkretny typ. Lista typów jest zazwyczaj bardzo długa i obejmuje przygotowanie etykiet dla najróżniejszych sytuacji. Wybór konkretnego typu ustala od razu parametry etykiet czyli ich rozmiar. Jeśli dysponujemy arkuszami etykiet, co do których nie mamy żadnych informacji o producencie i typie, możemy wybrać typ „[Użytkownik]” i samodzielnie zdefiniować wszystkie parametry etykiet i arkusza z etykietami. Należy w tym celu przejść do zakładki „Format”.
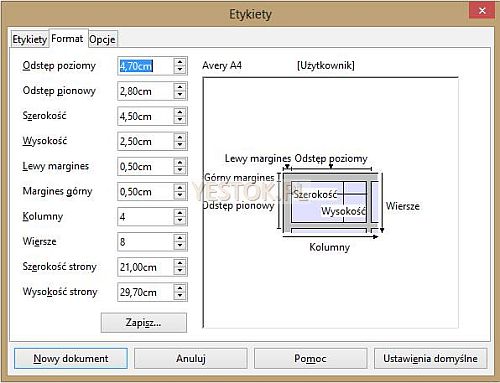
Nad ramką podglądu umieszczona jest wybrana marka i wybrany typ etykiety. W polach po lewej stronie zdefiniować można wszystkie niezbędne parametry opisujące etykiety i arkusz, na którym się znajdują.
- Pola „Szerokość” i „Wysokość” określają fizyczne rozmiary obszaru przeznaczonego na treść pojedynczej etykiety .
- Pola „Lewy margines” i „Margines górny” określają odległość pierwszej etykiety odpowiednio, od lewej i górnej krawędzi arkusza.
- „Odstęp poziomy” określa odległość między lewymi brzegami etykiet leżących w jednym wierszu.
- „Odstęp pionowy” określa odległość między górnymi brzegami etykiet leżących w jednej kolumnie.
- „Kolumny” i „Wiersze” określają ile kolumn i wierszy etykiet znajduje się na jednym arkuszu.
- „Szerokość strony” i „Wysokość strony” określają fizyczny rozmiar arkusza. Format A4 to wymiary 21,0 cm szerokości i 29,7 cm wysokości.
Podawane wartości są kontrolowane w ten sposób, że liczba etykiet określona wartościami wierszy i kolumn, musi zmieścić się na zadeklarowanym wymiarze arkusza. Podanie większej liczby spowoduje korektę wymiarów arkusza, bez ostrzegania użytkownika, że liczba kolumn i wierszy jest za duża.
Widoczny w dolnej części zakładki przycisk „Zapisz…”, pozwoli zapisać podane parametry jako nowy typ etykiet. Otwarte zostanie pokazane poniżej okno.

W okienku można rozwinąć listę „Marka” aby wybrać do której marki zostanie dopisana własna etykieta. W polu „Typ” wprowadza się nazwę.
Ostatnią zakładkę „Opcje”, przedstawia rys. 47.

Tutaj podejmuje się decyzję, czy drukowana ma być cała strona etykiet, czy etykieta pojedyncza.
Jeśli zostanie wybrana etykieta pojedyncza, to można wskazać, w której kolumnie, i jakim wierszu arkusza ma ona zostać umieszczona. Gdy wybrano opcję „Cała strona” to drukowanie etykiet zależy od treści etykiety. Jeśli treścią jest zwykły tekst, to jest on powielony we wszystkich etykietach na arkuszu. Gdy tekst zawiera choćby jedno pole ze źródła danych, to wartości pobierane z tego źródła będą umieszczane w kolejnych etykietach aż do ostatniego rekordu ze źródła.
Bardzo istotna jest widoczna opcja „Synchronizuj zawartość”, jeśli zostanie włączona jej znaczenie objawi się w następnym kroku przygotowywania etykiet. Tym kolejnym krokiem jest użycie przycisku „Nowy dokument”. Spowoduje on przekształcenie podanych parametrów w nowy dokument, którego widok przedstawia rys. 48.

Dokument ten można oczywiście zapisać pod własną nazwą. Postać dokumentu pokazanego na ilustracji zależy od tego czy włączone jest cieniowanie pól i czy są pokazywane nazwy pól. Tutaj obie te opcje były wyłączone i dlatego nazwy pól pokazane są w charakterystycznych ostrych nawiasach. Jeśli w treści etykiety znajdowałyby się także zwyczajne teksty, to są one umieszczone w każdej etykiecie. Gdy w zakładce „Opcje”, okna dialogowego „Etykiety”, zaznaczono „Synchronizuj zawartość”, to w dokumencie pojawi się, zaznaczony na ilustracji, przycisk „Synchronizuj etykiety”.
Może się okazać, że w gotowym dokumencie, zechcemy zmienić format niektórych elementów etykiety, np. w nazwisku zmienić krój czcionki i jej wielkość albo coś dopisać lub usunąć. Możemy takie poprawki realizować w dowolnej etykiecie i wprowadzone zmiany będą dotyczyły tylko jej. Jeśli jednak w dokumencie widoczny jest przycisk „Synchronizuj etykiety”, to zmiany i modyfikacje mogą być wprowadzane tylko do pierwszej etykiety. Natomiast kliknięcie tego przycisku spowoduje, że zostaną zastosowane we wszystkich pozostałych etykietach.
Drukowanie etykiet realizuje polecenie drukowania. Jeśli etykiety składają się wyłącznie ze zwykłego tekstu, drukowany jest pojedynczy arkusz i większą ich liczbę można określić w parametrach drukowania – ilością kopii. Gdy wybrano opcję „Pojedyncza etykieta”, to zostanie wydrukowana etykieta na konkretnej pozycji w arkuszu. Można w ten sposób wykorzystywać rozpoczęte, lecz nie do końca wykorzystane arkusze. Jeśli w etykiecie znajdują się pola ze źródła danych, to wydruk traktowany jest tak jak wydruk korespondencji seryjnej, i można wyselekcjonować rekordy do wydruku, stosując omówione już wcześniej zasady. Tutaj jednak trzeba wiedzieć, że jeśli etykiety mają mieszaną treść, to na wszystkich etykietach arkusza zostaną wydrukowane treści stałe, zaś zawartość pól, tylko na tylu etykietach, ile rekordów wybrano. Jeśli rekordów przeznaczonych do wydrukowania jest więcej niż etykiet na arkuszu, kolejne będą drukowane na następnych stronach.
Omyłkowy wybór drukowania pojedynczej etykiety zawierającej pola ze źródła danych, spowoduje że zostanie wydrukowanych tyle stron, zawierających jedną etykietę na wybranej pozycji, ile rekordów danych wyselekcjonowano do wydruku.
Załącznik testowy do pobrania.
Na zakończenie tematu korespondencji seryjnej, tym którym nie chce się tworzyć własnego źródła danych, a chcieliby przetestować jej działanie, umożliwiam pobranie źródła z przykładu użytego w tym opracowaniu .
Jeżeli chcecie Państwo pobrać plik, pamiętacie, że za taką możliwość odpowiada kliknięcie odnośnika (łącza) prawym przyciskiem myszki i wybranie z wyświetlonego menu pozycji w rodzaju „Zapisz element docelowy jako...” lub „Zapisz link jako...”. Kliknięcie lewym przyciskiem może spowodować inne działania niż pobieranie, gdyż przeglądarka może próbować bezpośredniego odczytania pliku. W szczególności, większość przeglądarek ma obecnie włączoną możliwość bezpośredniego odczytywania plików PDF.
Źródło jest plikiem arkusza kalkulacyjnego Calc. Aby je pobrać, proszę kliknąć łącze: zrodlo.ods